
The Week That Was: 2021-11-06 (November 6, 2021)
Brought to You by SEPP (www.SEPP.org)
The Science and Environmental Policy Project
Quote of the Week: “I don’t know what’s the matter with people: they don’t learn by understanding; they learn by some other way – by rote, or something. Their knowledge is so fragile!” – Richard Feynman
Number of the Week: $1,000,000,000,000 (One Trillion Dollars US)
THIS WEEK:
By Ken Haapala, President, Science and Environmental Policy Project (SEPP)
Scope: The Gala in Glasgow, better known as the UN 26th Conference of the Parties (COP) to the United Nations Framework Convention on Climate Change (UNFCCC), preempted the scope of this week’s TWTW. Perhaps, political economics columnist Joseph Sternberg of the Wall Street Journal stated it best.
President Biden hightailed it out of the COP26 climate confab in Glasgow before the returns from Tuesday’s U.S. elections were in, and just as well. Talk about an embarrassment—for the entire global-summit-industrial complex as much as for Mr. Biden personally or his party back home.
Tuesday’s electoral rebuke to America’s Democrats caps a nine-month span in which one has often wondered for whom Mr. Biden speaks. He doesn’t represent half of his party, although it’s hard to tell from day to day whether the half he does represent is the far-left progressive wing or the centrist faction. Neither seems particularly happy with him.
Bad results for Democrats in Virginia, and almost in New Jersey, suggest Mr. Biden’s party is losing its claim to represent the moderate swing voters who put him in office a year ago. So, when he signs on a dotted line at COP26 or anywhere else, the first question any foreign leader should ask is: Whose full faith and credit, exactly, stands behind this commitment?
This should embarrass the global-summit gang because it’s the same story everywhere else. Consider the Group of Seven, one of the older of the world’s many overlapping associations of nations. Its summer meeting in the U.K. paved the way for the policy breakthroughs of recent months, from a major new global corporate-tax deal to some of the green innovations to emerge from COP26. And of the leaders at the G-7’s table, only Britain’s Boris Johnson and French President Emmanuel Macron enjoyed any sort of clear-cut electoral mandate for anything, let alone for anything on the agenda at the summit.
As for the other world leaders making these decisions, Canadian Prime Minister Justin Trudeau, and German Chancellor Angela Merkel both lead minority governments (without and with a coalition partner). Or rather Ms. Merkel used to lead such a government. By the time she showed up in Glasgow for COP26 she didn’t represent anyone, having long ago announced she’d retire after the September elections in which her party’s proportion of the vote hit a postwar low.
Japan is on to its second of two prime ministers this year, only the more recent of whom won an election. Italian Prime Minister Mario Draghi hasn’t been elected by anyone, having come to power via obscure machinations among a kaleidoscopic array of parties in Rome. The European Union gets a seat at the G-7 table, too, and its democratic deficit—which in Europe is code for “crisis of legitimacy”—is longstanding, notorious and possibly unfixable.
These are the people negotiating global regulatory deals?
After discussing other issues (China’s Xi Jinping and Russia’s Vladimir Putin were no shows, and shows such as Prince Charles and Greta Thunberg hardly have a mandate from the public in their countries) Sternberg concludes with:
The problem isn’t, as is so commonly claimed, a lack of “political will” on the part of world leaders. They demonstrate extraordinary willfulness by daring to show up at all when no one elected them to do so. The problem is a lack of political mandate. [Boldface added]
Trying to bow to this reality while scrupulously avoiding a direct acknowledgment of it, COP26 delegates claimed to have found a workaround this week. They’ve ditched aspirations for bold political commitments from world leaders to curb carbon-dioxide emissions. Instead, they will foist major new green burdens onto private-sector investors, first and foremost banks and asset managers.
Talk about doubling down on a bad bet. If a mandate existed among global investors for this strategy, they would be investing accordingly already (and some are). This ploy merely shifts the argument from whether politicians have the legitimacy to offer up taxpayer money for the sake of climate mitigation to whether they have the legitimacy to monkey around with households’ pensions. Good luck with that.
As for domestic politics, it didn’t use to be the case that major parties in Western democracies routinely squeaked into power with scant pluralities and ideologically incoherent coalitions. That this has become the norm now might have to do with the fad for embracing the global causes of the roving activist class.
The Glasgow Gala is a showcase for empty suits bragging about the extent to which they will punish the people of their country. As Paul Homewood wrote about the no-show President of China:
“President Xi may make all sorts of promises about peaking emissions, reducing carbon intensity and carbon neutrality in 2060. The harsh reality, however, is that without fossil fuels, China would now be back in the Dark Ages.
“If Xi does not appreciate this, there are many on his Politburo who do, and they will quickly send him off to the re-education camps if he stands in their way.”
However, the representatives in Glasgow did say they had an agreement to stop methane leaks from the oil and gas industries, but which also occur in nature. Methane has the chemical symbol of CH4, and natural gas contains small amounts of other hydrocarbons as well. Given the overreach of the Biden Administration and regulatory agencies such as the EPA, the issues are what damage the Biden Administration will attempt to do to the thriving US natural gas industry, and what is the scientific justification? This TWTW will focus on the impact of methane on climate, then discuss several other deficiencies in the questionable science used by the UN Intergovernmental Panel on Climate Change (IPCC). See Article # 3 and links under Problems in the Orthodoxy.
*****************
From Depletion to Excess? Those involved with energy in the US during the Ford and Carter Administrations of the 1970s will recall long lines to buy gasoline and periods of sudden unemployment during cold winters when there was not enough natural gas to keep factories operating. Congress passed laws prohibiting the construction of new power plants using oil or natural gas as the primary fuel. Coal was the new miracle fuel.
In the 1990s we had the hysteria of “peak oil” with experts claiming the world was about to run out of oil. Now we have experts claiming the world is using too much coal, oil, and natural gas, causing the world to overheat. The US laws banning using oil and natural gas as the primary fuels for generating electricity were repealed. If the laws were still in effect, we would not have natural gas turbines generating electricity needed when wind and solar fail; and the ignorance of the empty suits in Glasgow would be more obvious, at least to Americans. See links under Challenging the Orthodoxy.
*****************
Three Papers: From 2019 to 2021 physicists W. A. van Wijngaarden & W. Happer produced three papers: 1) Methane and Climate; 2) Dependence of Earth’s Thermal Radiation on Five Most Abundant Greenhouse Gases; and 3) Relative Potency of Greenhouse Molecules. They use the HITRAN database to discuss the greenhouse effect as it occurs in the earth’s atmosphere. These papers have not been published by any western scientific journals. Apparently, editors of the journals are afraid of the political wrath of the supporters of IPCC “science” and its followers.
One of the problems with the hypothesis that hydrofluorocarbons (HFCs) deplete the earth’s ozone layer is that it may be true in the laboratory but may not be true in the atmosphere. The return of the ozone “hole” over Antarctica shows that the hypothesis has problems. Similarly, laboratory tests for the effects of greenhouse gases use dry air, an artificial concept. Even EPA members who live in the Washington area must see that in November automobiles parked outside are frequently covered with dew or frost. It is important to recognize what is actually happening in the actual atmosphere which the paper, Methane and Climate (2019), addresses.
Important graphs in the paper, Figures 4 & 5, use the widely accepted Stefan-Boltzmann law for blackbody radiation, which the IPCC ignored until its latest report, AR6 (2021) and still got wrong. A blackbody is an idealized concept for an object that absorbs all electromagnetic radiation that contacts it. The law states that the “total radiant heat power emitted from a surface is proportional to the fourth power of its absolute temperature.” A temperature rise from 2 K to 3 K is just 50%. But the amount of radiant heat power emitted from the surface is proportional to the fourth power of the temperature. Two to the fourth power is sixteen. Three to the fourth power is eighty-one, or more than five times sixteen. There is no linear relationship as implied by some studies used by the IPCC.
The abstract of Methane and Climate states:
“Atmospheric methane (CH4) contributes to the radiative forcing of Earth’s atmosphere. Radiative forcing is the difference in the net upwards thermal radiation from the Earth through a transparent atmosphere and radiation through an otherwise identical atmosphere with greenhouse gases. Radiative forcing, normally specified in units of W m-2, depends on latitude, longitude, and altitude, but it is often quoted for a representative temperature latitude, and for the altitude of the tropopause or for the top of the atmosphere. For current concentrations of greenhouse gases, the radiative forcing at the tropopause, per added CH4 molecule, is about 30 times larger than the forcing per added carbon dioxide (CO2) molecule. This is due to the heavy saturation of the absorption band of the abundant greenhouse gas, CO2. But the rate of the increase of CO2 molecules, about 2.3 ppm/year (ppm = part per million), is about 300 times larger than the rate of increase of CH4 molecules, which has been around 0.0076 ppm/year since 2008. So, the contribution of methane to the annual increase in forcing is one tenth (30/300) that of carbon dioxide. The net forcing increase from CH4, and CO2 increases is about 0.05 W m-2 year-1. Other things being equal, this will cause a temperature increase of about 0.012 C year. Proposals to place harsh restrictions on methane emissions because of warming fears are not justified by facts. [Boldface added]
The increase of about 0.012 C per year is the same as Roy Spencer is reporting in the linear trend from 42 years of satellite measurements of atmospheric temperature trends over oceans (0.12 C per decade).
The authors discuss the effects of computationally changing the concentration of CO2, which they show in their figure 5. There is a black curve for present day concentration (f = 1), a red curve for doubled concentration (f = 2), and perhaps most important, a green curve for completely zeroing-out all CO2 (f = 0). Figure 5 makes clear that CO2 has an important greenhouse effect; but at its current concentrations its effectiveness is already greatly diminished, and doubling its concentration makes only a very tiny difference. The greenhouse effect of CO2 is said to be saturated. In the last paragraph, the authors define saturation:
“The reason that the per-molecule forcing of methane is some 30 times larger than that of carbon dioxide for current concentrations is saturation of the absorption bands. “Saturation” means that adding more molecules causes very little change in Earth’s thermal radiation to space. The current density of CO2 molecules is some 200 times greater than that of CH4 molecules, so the absorption bands of CO2 are much more saturated than those of CH4. In the dilute “optically-thin” limit, WH [1] show that the tropospheric forcing power per molecule is P{i} = 0.51×10−22 W for CH4, and P{i} = 2.73×10−22 W for CO2. Each CO2 molecule in the dilute limit causes about 5 times more forcing increase than an additional molecule of CH4, which is only a “super greenhouse gas” because there is so little in the atmosphere, compared to CO2,” [Boldface added]
The authors also discuss feedbacks which are a critical part of the extreme claims of the IPCC. These will be discussed in the next TWTW with the discussion of the other two recent papers by Wijngaarden & Happer. Also, it is important to note that the entire discussion is based on cloudless skies. No one has developed an acceptable hypothesis on clouds. The October 23 TWTW links to papers by Fritz Vahrenholt and Hans-Rolf Dübal suggesting that much of the warming of the past 20 years may be due to a reduction in clouds. See links under Challenging the Orthodoxy, the October 23 TWTW, and Measurement Issues – Atmosphere.
*****************
The Trick and the Hack: Along with econometrician Ross McKitrick, statistician Stephan McIntyre was responsible for exposing “The Trick” used by Mr. Mann and the IPCC in the infamous “hockey-stick.” McIntyre writes:
“Two major new BBC programs, The Trick and the Hack That Changed the World, re-visit 2009 Climategate events on the eve of UK hosting the most recent international climate get-together. I was interviewed by The Hack and mentioned in The Trick as a villain.”
On November 1, McIntyre wrote his current views on the Climategate Hacker:
“Subsequent to my interview with the Hack That Changed, I’ve re-examined and cross-checked documents and noticed some interesting new connections. I don’t know the identity of the Climategate hacker, but do believe that deductions about his profile (e.g., motivated individual vs paid institutional hacker) can be made more intelligently by carefully examining details of what was exfiltrated and when – as I shall do here.”
McIntyre’s detective work and logic are interesting, and he concludes:
“Nothing in the hacking technique or timeline points to Russian intel services or US fossil fuel corporations. I don’t know the identity of the Climategate hacker, nor do I even have a guess. What we do know is what we knew more or less since the beginning: that Mr FOIA was a reader of Climate Audit, Watts Up, Real Climate and other climate blogs; that he was careful both in his use of proxy servers; and that, unlike Guccifer 2, he had no interest in leaving a massive social media trail.”
His November 2 post on “The Decline, the Stick and The Trick – Part 1” is more interesting because it goes to a current problem continuing in the studies used by the IPCC, especially in the Summary for Policymakers (SPM, AR6, 2021) and its followers. McIntyre begins:
“One of the central claims of The Trick, if not the most central claim, was that ‘hiding the decline’ was nothing more than an inopportune phrase about a single diagram.
“It wasn’t.
“The ‘trick to hide the decline’ was an inopportune, if revealing, phrase. However, rather than the issue being limited to a single diagram, the inconsistency between the Decline (in observed tree ring widths and densities) and the Hockey Stick temperature reconstructions (primarily based on tree ring widths) was, the real issue… it was the issue that inspired my original examination of Michael Mann’s Hockey Stick. That was the driving theme of Climate Audit from its origin up to Climategate. There are dozens, even hundreds, of Climate Audit articles that, in one way or another, relate back to the conundrum arising from the inconsistency of the underlying proxies and the superficial consistency of the reconstructions. [Edited]
“In this and a couple of follow-on articles, I’ll illustrate the centrality of The Decline vs The Stick in the controversies in the years prior to Climategate. For the benefit of people that may be new to these disputes, I re-iterate that I never interpreted the late 20th century decline in ring widths as evidence of a decline in temperatures, but as a seriously problematic inconsistency for ‘reconstructions’ relying in large part on tree rings.” [Boldface in original]
McIntyre carefully explains his views which he plans to be part of a series. In a post at the bottom of the essay on The Hack, research professor Donald Rapp summed the issues well. He wrote (in response to the post):
I think the arguments presented are credible – there was a simple hack most likely based on a simple entry. But from my point of view, I don’t care if the world’s worst villains were responsible for the hack, nor am I concerned with the degree of sophistication used to get into these secret files. What does matter is that as of 2009, it is clear that the climate science tribe was strongly biased in favor of alarmism and built their arguments around dubious data and worse manipulation of the data, complete with cherry picking some and hiding others, while at the same time using their influence to squelch alternative views and punish those not in the tribe. It became clear that the whole science of proxies for past climate was rife with fake news. Any proxy requires a standardization period when the model can be compared to data. Then, extrapolation to previous eras requires justification by showing that other variables were comparable during the extrapolated period to those during the standardization period. I have read dozens of published papers that utilize proxies. Very few if any show the comparison during the standardization period and/or the basis for justifying extrapolation. I came to the reluctant conclusion that almost all the proxy data is highly suspect. SM [Steve McIntyre] penetrated far more deeply than I did into the proxies used by MBH and demonstrated the fallacies in both the proxies themselves as well as the methods of processing data. It seems unimaginable that after all the demonstrations by SM over a decade and more, they are still putting forth their un-science and Mann still is a highly respected leader in the climate field. The climate gate releases demonstrated not so much the details (they were revealed by SM) as much as the mindset of these rascals. Altogether, the events of 2009 cast a very long shadow on the periodic UN reports that came out subsequently. Can you believe anything that the climate establishment publicizes? [Boldface added]
The latest Summary for Policymakers features the latest “hockey-stick” by an international paleoclimatology group based in Bern, Switzerland, known as PAGES 2k (PAst Global ChangES with 2k referring to the past 2000 years). Their “hockey-stick” is a collection of bits and pieces cobbled together. It is similar to presenting a table made of chipboard (particle board) (wood chips and glue) as solid oak. See links under Climategate Continued.
*****************
Dangerous Bureaucracies: Power engineer Donn Dears wrote of the actions that General Electric CEO Jack Welch took to increase productivity and the company’s prosperity. Welch fiercely cut back on bureaucracy at GE headquarters and elsewhere. In his short essay, Dears brings up the book Parkinson’s Law and Other Studies in Administration. With its false claims of science, has the IPCC become a dangerous bureaucracy? See link under Challenging the Orthodoxy.
*****************
The Best and The Brightest? Last year a featured spokesperson for the UN for its claims of a climate crisis was the darling teenager, Greta Thunberg. This year she is leading obscene chants against the UN COP 26 for inaction on climate. The UN chose a new darling of the day – a small T. Rex! The UN is sponsoring advertisements broadcast on US national television (CBS) featuring a small T. Rex warning a UN audience about the dangers of climate change. This is doubly absurd. One, the geological evidence indicates that the dinosaurs lived between 245 and 66 million years ago when the earth was much warmer and CO2 concentrations were far greater. Two, they were probably wiped out by a sudden global cooling caused when an asteroid hit near the Yucatan Peninsula, not by global warming.
Is this the best the brightest at the UN can do? At least they don’t have to worry about T. Rexes leading obscene chants against them. See links under Below the Bottom Line.
*****************
Number of the Week: $1,000,000,000,000 (One Trillion Dollars US). According to reports China and a group of other countries are demanding One Trillion Dollars to limit CO2 emissions. If they receive it, China’s leader Xi Jinping will have breathing room to use against his fellow members of the Politburo. See links under Funding Issues.
NEWS YOU CAN USE:
Science: Is the Sun Rising?
New Study With Groundbreaking Results: “Connection Between Cosmic Rays, Radiation Budget Reaffirmed”
By P Gosselin, No Tricks Zone, Oct 31, 2021
Link to paper: Atmospheric ionization and cloud radiative forcing
By Henrik Svensmarkm Jacob Svensmark, Martin Bødker Enghoff & Nir J. Shaviv, Nature Scientific Reports, Oct 11, 2021
A Theory of the Hack
By Steve McIntyre, Climate Audit, Nov 1, 2021
The Decline, the Stick and The Trick – Part 1
By Stephen McIntyre, Climate Audit, Nov 2, 2021
Challenging the Orthodoxy — NIPCC
Climate Change Reconsidered II: Physical Science
Idso, Carter, and Singer, Lead Authors/Editors, Nongovernmental International Panel on Climate Change (NIPCC), 2013
Summary: https://www.heartland.org/_template-assets/documents/CCR/CCR-II/Summary-for-Policymakers.pdf
Climate Change Reconsidered II: Biological Impacts
Idso, Idso, Carter, and Singer, Lead Authors/Editors, Nongovernmental International Panel on Climate Change (NIPCC), 2014
http://climatechangereconsidered.org/climate-change-reconsidered-ii-biological-impacts/
Summary: https://www.heartland.org/media-library/pdfs/CCR-IIb/Summary-for-Policymakers.pdf
Climate Change Reconsidered II: Fossil Fuels
By Multiple Authors, Bezdek, Idso, Legates, and Singer eds., Nongovernmental International Panel on Climate Change, April 2019
http://store.heartland.org/shop/ccr-ii-fossil-fuels/
Download with no charge:
Why Scientists Disagree About Global Warming
The NIPCC Report on the Scientific Consensus
By Craig D. Idso, Robert M. Carter, and S. Fred Singer, Nongovernmental International Panel on Climate Change (NIPCC), Nov 23, 2015
http://climatechangereconsidered.org/
Download with no charge:
Nature, Not Human Activity, Rules the Climate
S. Fred Singer, Editor, NIPCC, 2008
http://www.sepp.org/publications/nipcc_final.pdf
Global Sea-Level Rise: An Evaluation of the Data
By Craig D. Idso, David Legates, and S. Fred Singer, Heartland Policy Brief, May 20, 2019
Challenging the Orthodoxy
By W. A. van Wijngaarden & W. Happer, CO2 Coalition, Nov 26, 2019
Dependence of Earth’s Thermal Radiation on Five Most Abundant Greenhouse Gases
By W. A. van Wijngaarden & W. Happer Atmospheric and Oceanic Physics, prepublication, Dec 22, 2020
Relative Potency of Greenhouse Molecules
By W. A. van Wijngaarden and W. Happer, Prepublication, January 14, 2021
CLINTEL to IPCC/COP26: AR6 Summary for Policymakers Flawed
By Robert Bradley Jr., Master Resource, Nov 4, 2021
“We conclude that the AR6 WG1 SPM regrettably does not offer an objective scientific basis on which to base policy discussions at COP26. It also fails to highlight the positive impacts of slightly increased CO2 levels and warming on agriculture, forestry and human life on earth.”
COP26 at Odds with Leaders of Nearly 40 Percent of World’s People, Likely to Fail
India alone is a huge thorn in the sides of the Glasgow glitterati
By Vijay Jayaraj, The American Spectator, Oct 31, 2021
[SEPP Comment: The 40% of the world that western opinion fabricators assume does not exist.]
COP26 And The Hubris Of Our Political Overlords
By Francis Menton, Manhattan Contrarian, Oct 31, 2021
Manhattan Contrarian Announces The Arrival Of “Peak Oil-Hysteria”
By Francis Menton, Manhattan Contrarian, Nov 3, 2021
From the Wall Street Journal: “…The effort spotlighted growing concerns about the environmental harms of methane, a byproduct of drilling. . . .” [Boldface added]
Nigel Lawson: Net zero is a disastrous solution to a nonexistent problem
By Paul Homewood, Not a Lot of People Know That, Nov 4, 2021
“The climate hysteria is by no means a harmless folly. The reason the world uses fossil fuels is that they are far and away the cheapest source of large-scale reliable energy. Nuclear power is reliable, but not cheap. Renewables — wind and sun — are not particularly cheap and certainly not reliable (the wind doesn’t always blow, nor does the sun always shine).”
Dangerous Bureaucracies
By Donn Dears, Power For USA, Nov 2, 2021
Does environmental stress drive migration?
New comprehensive analysis ranks environmental and social factors for explaining migration globally as well as in each country—and it’s more complicated than previous understanding suggests
Press Release by Aalto University, Nov 5, 2021 [H/t WUWT]
Link to paper: Global migration is driven by the complex interplay between environmental and social factors
By Venla Niva, et al, Environmental Research Letters, Oct 26, 2021
From the abstract: “Regardless of the income level, income was the key factor in explaining net-migration in half of the countries.”
The madness of clouds (II)
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Link to post: 2001-2019 Warming Driven By Increases In Absorbed Solar Radiation, Not Human Emissions
By Kenneth Richard, No Tricks Zone, Oct 18, 2021
Defending the Orthodoxy
IPCC AR6: Severe convective storms, unspun edition
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Defending the Orthodoxy – Bandwagon Science
Importance of Methane
By Staff, EPA, Accessed Nov 3, 2021
“Methane is more than 25 times as potent as carbon dioxide at trapping heat in the atmosphere.”
Neil Oliver Sums Up The Hypocrisy
By Paul Homewood, Not a Lot of People Know That, Nov 2, 2021
[SEPP Comment: If there is a crisis caused by CO2, why not use Zoom for tens of thousands of “special people” rather than fly them in? Should the “special people” live lives of poverty as St. Francis did? Should they not walk the walk?]
Robust detection of forced warming in the presence of potentially large climate variability
By Sebastian Sippel, et al. AAAS Science Advances, Oct 22, 2021
“We find a best estimate forced warming trend of 0.8°C over the past 40 years, slightly larger than observed.”
[SEPP Comment: Based on what evidence?]
Why the so-called “energy crisis” is both a threat and an opportunity
This is a moment to accelerate the transition towards net zero, not to retreat.
By Adam Tooze, New Statesman, UK, Oct 27, 2021
“The energy transition is a historic experiment. We are all going to have our moments of panic and disbelief. We are all going to have to battle with our ghosts, with nostalgia and with deep-seated fears from the past. It will be a steep learning curve. It may be a turbulent journey. But the one thing that we can be certain of – and 2021 confirms it – is that the status quo offers no safety.”
[SEPP Comment: We have nothing to lose except our prosperity and reliable electricity?]
Questioning the Orthodoxy
The climate moaners need to get some perspective from history
By Ian Plimer, Spectator, AU, Nov 2, 2021 [H/t Edward Harinck]
Because it’s rubbish
By John Robson, Climate Discussion Nexus, Nov 3, 2021
COP 26: Methane madness
By David Wojick, CFACT, Nov 4, 2021
“Here is how Climate Home News put it: ‘The US and EU got more than a hundred countries on board with a commitment to cut methane emissions 30% by 2030, putting oil and gas sector leakage in the spotlight’.”
Emissions, Error and Innumeracy as a Guiding Policy
By Peter O’Brien, Quadrant, Nov 2, 2021
“I should have known that, as Michael Kile recently pointed out, sophistry is the lifeblood of the alarmists and any inconvenient ‘inconvenient truth’ can be rationalised away.”
DAN WOOTTON: I want to save the planet but I resent being told how to do it by a bunch of biased BBC reporters, unelected billionaires, royals, celebrities and tone-deaf politicians whose private jets have turned Flop 26 into an orgy of hypocrisy
By Dan Wootton, Daily Mail.com, Nov 3, 2021 [H/t Paul Homewood]
“I don’t know which image of unbridled hypocrisy, sickening privilege and total tone-deafness made me fume more.”
COP26 Eco-Imperialism Threatens the World’s Poor
Climate alarmists want poor nations kept poor. Poor nations want trillions in compensation.
By Craig Rucker, Real Clear Energy, Nov 2, 2021
1979 UN Global Cooling Conference
By Tony Heller, His Blog, Nov 4, 2021
“In 1979, the World Meteorological Organization gathered 450 experts to discuss the threat of global cooling.”
AEF Climate News – November 2021
By Alan Moran, Climate News, AU, Nov 1, 2021 [H/t ICECAP]
Climate Geniuses
By Tony Heller, His Blog, Nov 5, 2021
Video
Ten Hypocritical Moments Surrounding Glasgow Cop26 Climate Change Summit
As the mega-rich descend on Glasgow with their private jets and gas-guzzling cars, critics accuse global leaders of “do as I say, not as I do”.
By Sophia Sleigh, Huff Post, Nov 1, 2021
“A parade of more than 400 private jets carrying world leaders and business executives are thought to be flying in for the summit.
“Scotland’s Sunday Mail estimated the flights will blast 13,000 tonnes of CO2 into the atmosphere – more global warming gas than 1,600 Scots burn through in a year.”
After Paris!
After 26 COP meetings we are a Fossil Fueled World: Coal, oil gas give us 80% of the energy on Earth
By Jo Nova, Her Blog, Nov 5, 2021
Glasgow: The Stampede To Mass Poverty…120 BILLION Tonnes Of Materials For Wind Turbines By 2050?
Commentary by Fred F. Mueller, No Tricks Zone, Nov 3, 2021
Major methane deal at climate summit — without China
By Patrick Galey and Jitendra Joshi, Glasgow (AFP) Nov 2, 2021
The tragi-comic climate doomsday cult
World leaders have made complete fools of themselves at COP26
By Melanie Phillips, Her Blog, Nov 2, 2021
“No wonder Russia and China didn’t even bother to turn up to COP26. Their contempt for the west must be bottomless as they look upon its accelerating economic and cultural green suicide — and rub their hands.”
Biden apologizes for US withdrawing from Paris deal under Trump
By Morgan Chalfant, The Hill, Nov 1, 2021
18 countries commit to coal phase out
By Rachel Frazin, The Hill, Nov 3, 2021
Biden’s 85-vehicle motorcade a textbook example of hypocrisy from ‘limousine liberals’: Boothe
‘The Big Saturday Show’s’ panelists uncovered the ‘rules for thee, but not for me’ hypocrisy of the modern left
By Graham Colton, Fox News, Nov 1, 2021
Change in US Administrations
FACT SHEET: President Biden Renews U.S. Leadership on World Stage at U.N. Climate Conference (COP26)
Press Release, The White House, Nov 1, 2021
Biden warns of ‘existential’ climate threat at Glasgow summit
By Morgan Chalfant and Rachel Franzin, The Hill, Nov 1, 2021
Biden seeks to reassert US leadership on climate
By Rachel Frazin and Morgan Chalfant, The Hill, Nov 1, 2021
Were Biden’s Claims at COP26 Climate Change Summit Accurate?
By Christian Mysliwiec, The Daily Signal, Nov 3, 2021
Granholm touts ‘really exciting’ provision in infrastructure bill at COP26
By Zack Budryk, The Hill, Nov 5, 2021
“Energy Secretary Jennifer Granholm touted funding in the bipartisan infrastructure bill for direct-air capture demonstration projects, calling the provision ‘really exciting’ during an address at the COP26 international climate summit in Glasgow, Scotland, on Friday.”
UN Showdown Needn’t Be America’s Last Stand on Climate
By Heather Reams, Real Clear Energy, Nov 4, 2021
“Alas, my organization [Citizens for Responsible Energy Solutions] analyzed his [Biden’s] proposal and concluded, given available technologies, that target cannot be achieved without catastrophic costs to the U.S. economy and workforce. Additionally, this feat would necessitate shifting our emissions to countries with far weaker regulations—and if his randomly chosen benchmark proves wholly unattainable, America’s leadership will be undermined.”
U.S. Energy Independence in Danger
By Staff, Institute for Energy Research, Nov 3, 2021
Problems in the Orthodoxy
Xi and Vlad Leave Two Open Chairs at Glasgow Climate Crisis Gala
By Larry Bell, Newsmax, Nov 3, 2021
China Still Burning More & More Coal
By Paul Homewood, Not a Lot of People Know That, Nov 5, 2021
COP26 aims to banish coal. Asia is building hundreds of power plants to burn it
By Sudarshan Varadhan and Aaron Sheldrick, Reuters, Oct 31, 2021
‘Saved by coal’: Far from COP26, another reality in India
While getting rid of coal may be possible for some developed nations, it is not so simple for developing countries.
By Staff, Aljazeera, Nov 1, 2021
55 New Coal Power Stations Under Construction In India
By Paul Homewood, Not a Lot of People Know That, Nov 4, 2021
Modi Speech–No Emissions Cuts Before 2030
By Paul Homewood, Not a Lot of People Know That, Nov 4, 2021
“I’ve tracked down the official translation from Hindu of Modi’s speech at COP26, which gives some clarification:”
[SEPP Comment: Give me the money first!]
Models v. Observations
Swiss Analysis: Climate Models Running Too Warm, Falsely Calibrated…IPCC Needs “To Review Its Findings”
By P Gosselin, No Tricks Zone, Oct 30, 2021
Model Issues
Suppressed Late-20th Century Warming in CMIP6 Models Explained by Forcing and Feedbacks
By Christopher J. Smith, Piers M. Forster, Geophysical Research Letters, Sep 13, 2021
“For the 1960–2000 period, the latest generation of climate models (Coupled Model Intercomparison Project Phase 6 [CMIP6]) shows less global mean surface temperature change relative to pre-industrial than that seen in observations.”
[SEPP Comment: When pressed, models can explain anything!]
Measurement Issues — Surface
Nobody goes there anymore, it’s too crowded
By John Robson, Climate Discussion Nexus, Nov 3, 2021
[SEPP Comment: Urbanization is causing crowding! And increasing surface temperatures.]
@COP 26: Tokyo Hasn’t Seen Any Warming In October In 30 Years…No October Warming In Sapporo Either
Charts by Kirye, Text by Pierre, NO Tricks Zone, Nov 2, 2021
1920 or 2020? Cape Leeuwin Australia edition
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Measurement Issues — Atmosphere
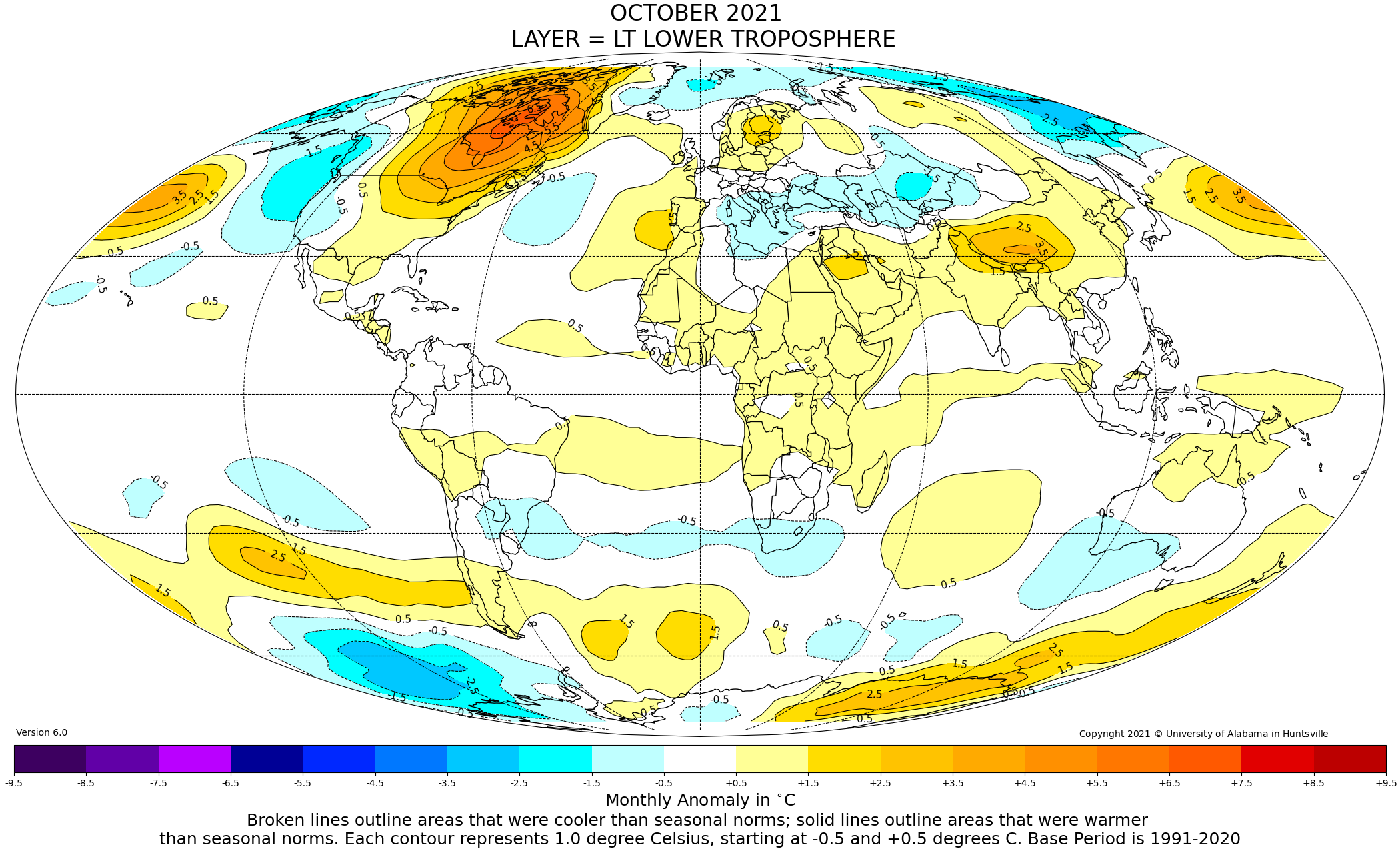
UAH Global Temperature Update for October, 2021:+0.37 deg. C.
By Roy Spencer, His Blog, Nov 1, 2021
http://www.drroyspencer.com/2021/11/uah-global-temperature-update-for-october-20210-37-deg-c/
Global Temperature Report
By Staff, Earth System Science Center, The University of Alabama in Huntsville, October 2021
Map: https://www.nsstc.uah.edu/climate/2021/october%202021/202110_Map.png
Graph: https://www.nsstc.uah.edu/climate/2021/october%202021/202110_Bar.png
Link to report: https://www.nsstc.uah.edu/climate/
Changing Weather
11 Feet of Snow Pounds Alaskan Ski Resort, Asia Braces for a Harsh Winter,
By Cap Allon, Electroverse.net, Nov 2, 2021 [H/t Dennis Ambler]
March 1936 Flooding
By Tony Heller, His Blog, Nov 4, 2021
October 1941
By Paul Homewood, Not a Lot of People Know That, Nov 5, 2021
“Which just goes to show that you can just about expect anything where British weather is concerned!”
Changing Climate
A Hundred Years Of Climate Change
By Paul Homewood, Not a Lot of People Know That, Nov 1, 2021
“While the global elite are trying to restructure our society in the name of the climate, we need to understand just how little our weather has actually changed.”
Earth’s orbit affects millennial climate variability
By Staff Writers, Beijing, China (SPX) Nov 03, 2021
Link to paper: Persistent orbital influence on millennial climate variability through the Pleistocene
By Youbin Sun, et al, Nature Geoscience, Nov 1, 2021
Holocene CO2 Variability and Underlying Trends
By Renee Hannon, CO2 Science, Oct 31, 2021
http://www.co2science.org/articles/V24/oct/a1.php
Changing Seas
Cyclones Downs, Corals Up – Except in Glasgow
By Jennifer Marohasy, Her Blog, Nov 4, 2021
Marine microbes more effective reducing methane than expected
By Staff Writers, Stockholm, Sweden (SPX) Nov 03, 2021
Distinct methane-dependent biogeochemical states in Arctic seafloor gas hydrate mounds
By Scott A. Klasek, Nature Communications, Nov 2, 2021
[SEPP Comment: They have been eating the stuff for several hundred million years.]
Changing Cryosphere – Land / Sea Ice
1,000 years of glacial ice reveal ‘prosperity and peril’ in Europe
Evidence preserved in glaciers provides continuous climate and vegetation records during major historical events
Press Release, American Geophysical Union, Nov 3, 2021 [H/t WUWT]
Link to paper: Alpine Glacier Reveals Ecosystem Impacts of Europe’s Prosperity and Peril Over the Last Millennium
By S. O. Brugger, et al. Geophysical Research Letters, Sep 23, 2021
“Microfossil data indicate that before 1750 CE forests and fallow land rapidly replaced crop cultivation during historically documented societal crises caused by climate shifts and epidemics.”
[SEPP Comment: The perils of the Little Ice Age, something the UN IPCC AR6 SPM ignores!]
Meltwater runoff from Greenland becoming more erratic
By Staff Writers, Paris (ESA), Nov 04, 2021
Link to paper: Increased variability in Greenland Ice Sheet runoff from satellite observations
By Thomas Slater, et al. Nature Communications, Nov 1, 2021
The ‘Hypothesis’ That Longwave (Greenhouse Gas) Forcing Drives Greenland Ice Melt Is Wrong
By Kenneth Richard, No Tricks Zone, Nov 4, 2021
Link to latest paper: Greenland Surface Melt Dominated by Solar and Sensible Heating
By Wenshan Wang, Geophysical Research Letters, Mar 27, 2021
See links immediately above
Changing Earth
Clear Evidence of a Low Altitude Cometary Air Burst Over the Atacama Desert ca. 12,000 Years Ago
By David Middleton, WUWT, Nov 4, 2021
Link to paper: Widespread glasses generated by cometary fireballs during the late Pleistocene in the Atacama Desert, Chile
By Peter H. Schultz, et al. Geology, Nov 2, 2021
The silent build-up to a super-eruption
By Staff Writers, Geneva, Switzerland (SPX), Nov 02, 2021
Growth and thermal maturation of the Toba magma reservoir
By Ping-Ping Liu, et al. PNAS, Nov 9, 2021
Agriculture Issues & Fear of Famine
Do Glaswegians Mostly Breathe Nitrogen?
By Jennifer Marohasy, Her Blog, Oct 30, 2021
Global climate change impact on crops expected within 10 years
By Ellen Gray for GSFC News, Greenbelt MD (SPX), Nov 02, 2021
Link to paper: Climate impacts on global agriculture emerge earlier in new generation of climate and crop models
By Jonas Jägermeyr, Nature Food, Nov 1, 2021
[SEPP Comment: More incompetence from NASA-GISS in using five CMIP6 climate models that fail basic testing against the physical atmosphere.]
Nearly 30,000 facing ‘climate change famine’ in Madagascar: UN
By AFP Staff Writers, Geneva (AFP) Nov 2, 2021
[SEPP Comment: Famine never happened before? World grain reserves are overflowing!]
Lowering Standards
Global population size estimates for polar bears clash with extinction predictions
By Susan Crockford, Polar Bear Science, Oct 31, 2021
“How many polar bears are there in the world? This was the primary question the International Union for Conservation of Nature (IUCN) had for the newly-formed Polar Bear Specialist Group (PBSG) back in 1968.”
“The problem with polar bear population size estimates is not that they represent a divide between science and public interests. The issue is that the PBSG has failed to fulfill its IUCN mandate in an honest and transparent manner and individual PBSG members gas-light the public whenever anyone suggests that polar bear numbers have increased rather than declined.
“What they are doing is advocacy, not science. The IUCN should be ashamed it has allowed this to happen.”
BBC’s Justin Rowlatt Loses It
By Paul Homewood, Not a Lot of People Know That, Nov 1, 2021
“This kind of belligerent hectoring is totally unacceptable from our supposedly impartial national broadcaster. It proves that the BBC is now simply a lobbyist for draconian climate alarmism, and is not interested in the facts or any sort of balanced debate.”
End of The World Harrabin Needs A Pulpit, Not A Job At The BBC
By Paul Homewood, Not a Lot of People Know That, Nov 3, 2021
Communicating Better to the Public – Use Yellow (Green) Journalism?
Hilarious Writeup of the Heartland Climate Conference
By Eric Worrall, Nov 2, 2021
‘Already too late’ to save Churchill polar bears claim a false NY Times climate change cliché for COP26
By Susan Crockford, Polar Bear Science, Nov 4, 2021
Making arguments is just so tiring
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Communicating Better to the Public – Exaggerate, or be Vague?
No, Roanoke Times, Climate Change Is Not To Blame for Virginia Beach’s Flooding
By H. Sterling Burnett, Climate Realism, Nov 5, 2021
Link to report: Land Subsidence and Relative Sea-Level Rise in the Southern Chesapeake Bay Region
By Jack Eggleston and Jason Pope, USGS, 2013
[SEPP Comment: Fig 9 of the report shows that land compaction around groundwater withdrawal centers at West Point (off the York River) and Franklin are the primary cause of sinking. “Land subsidence in the Hampton Roads area of the southern Chesapeake Bay region has averaged about 3 mm/yr since 1940. Measured rates range from 1.1 to 4.8 mm/yr.”]
Claim: 52F – 59F Annual Average is a “Fundamental” Climate Constraint
By Eric Worrall, WUWT, Nov 2, 2021
Increases in extreme humid-heat disproportionately affect populated regions
The world is not only getting hotter but also more humid
Press Release, NSF, Nov 2, 2021
Link to paper: Recent Increases in Exposure to Extreme Humid-Heat Events Disproportionately Affect Populated Regions
By Cassandra D. W. Rogers, et al, Geophysical Research Letters, Sep 17, 2021
[SEPP Comment: More “evidence” that humans are unfit to live in the tropics where they evolved? Why the great increase in urbanization world-wide?]
Communicating Better to the Public – Make things up.
The spectre of the impossible
By Tim Worstall, Net Zero Watch, Nov 2, 2021
[SEPP Comment: Exposing that an article in the Financial Times relies on modeling that uses unfeasible assumptions!]
Seth’s Nature Trick
By Paul Homewood, Not a Lot of People Know That, Oct 30, 2021
[SEPP Comment: National International Fire Center hiding data before 1983, A Tony Heller Video TWTW missed!]
Great Barrier Reef’s future dealt blow as study finds only 2% escaped coral bleaching
New research comes months after Australian government lobbied to keep coral reef off world heritage ‘in danger’ list
By Graham Readfearn, The Guardian, Nov 4, 2021 [H/t Bernie Kepshire]
[SEPP Comment: Does not mean the corals died!]
Glasgow Airport Threatened By 26 Feet Sea Level Rise
By Paul Homewood, Not a Lot of People Know That, Oct 30, 2021
“I expect this reporter also thinks there are fairies at the bottom of the garden!”
Report: Fine particles in air cause 4M premature deaths a year
By Rich Klein, Washington DC (UPI), Nov 2, 2021
[SEPP Comment: The accompanying map shows a remarkable decline in PM2.5 in China, particularly south of Beijing and north of Wuhan, and a remarkable increase in desert dust!]
Communicating Better to the Public – Use Propaganda
Glasgow Fighting Climate Change
By Paul Homewood, Not a Lot of People Know That, Oct 29, 2021
“In today’s propaganda bulletin, the BBC has presented one of those mindbogglingly boring educational pieces about Glasgow, for people who apparently don’t know that the city used to be full of slums and built ships:
“I really would not bother reading it!”
Communicating Better to the Public – Use Propaganda on Children
Climate Scientists to Their Kids: We’re Going to Die Like the Dinosaurs
By Eric Worrall, WUWT, Nov 4, 2021
Expanding the Orthodoxy
Climate Doom Pantomime at Glasgow, the hottest party for the Uber Rich to jet into on Fossil Fuels
By Jo Nova, Her Blog, Nov 3, 2021
Questioning European Green
Green suicide
Babiš criticised the European climate package in Glasgow
By Staff, Czech Press Agency, Via Lubos Motl, The Reference Frame, Nov 1, 2021
What Will Net Zero Cost You
By Paul Homewood, Not a Lot of People Know That, Oct 31, 2021
Video on actual costs to UK citizens.
[SEPP Comment: Once you establish policies, technologies will be established?]
Questioning Green Elsewhere
The security threats of Net Zero: One of 36 Stratagems to defeat the enemy
By Jo Nova, Her Blog, Oct 29, 2021
Link to report: The Worm in the Rose
By Gwythian Prins, GWPF, Press Release, Oct 23, 2021
Zero means zero… energy
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Biden Peddles Green New Deal to UN While U.S. Economy Suffers
By Ron Estes, Real Clear Energy, Nov 01, 2021
Serfing the planet
Green policies will accelerate the immiseration of the global working and middle class.
By Joel Kotkin, Spiked, Nov 1, 2021
Funding Issues
China and India Demand a TRILLION Dollars to Reduce CO2 Emissions
By Eric Worrall, WUWT, Nov 3, 2021
Climate summit president: Developed countries will ‘likely’ commit more than $500 billion in climate finance
By Zack Budryk, The Hill, Nov 3, 2021
The Political Games Continue
Great Speech: The Oil execs are owed an apology
By Jo Nova, Her Blog, Oct 30, 2021
“Florida Rep Byron Donalds let’s rip on the committee’s intimidation tactics, on their rank infringement of freedoms to speak, to do business, and to hold opinions.”
Energy Issues – Non-US
How Climate Activists Caused The Global Energy Crisis – OpEd
By Michael Shellenberger, Eurasia Review, Oct 27, 2021
Energy Issues — US
Economic trouble to worsen for ALL Americans (and Europeans)
By Staff, ICECAP, Oct 17, 2021
http://icecap.us/index.php/go/joes-blog/economic_trouble_to_worsen_for_most_amercians/
Oil and Natural Gas – the Future or the Past?
Louisiana Is Leading America’s LNG Boom
By Haley Zaremba, Oil Price.com, Nov 2, 2021
“The natural gas sector will be vulnerable to the same vicious storms, which will only continue to worsen in the coming years, in no small part thanks to the continued development of the selfsame industry.”
[SEPP Comment: Hurricanes never hit Louisiana before?]
Return of King Coal?
Coal keeps lights on at COP26 as low wind strikes again
By John Constable, Net Zero Watch, Nov 3, 2021
Link to paper: REALISM OR UTOPIANISM?: A proposal for reform of Net Zero policy
By John Constable and Capell Aris, GWPF, 2021
Nuclear Energy and Fears
Reemergence Of Energy Sanity? Europe Now Considers Nuclear, Natural Gas As Sustainable
By P Gosselin, No Tricks Zone, Oct 29, 2021
Stop burning trees! Go for nuclear and gas to go green
By Staff, Net Zero Watch, Nov 5, 2021
Alternative, Green (“Clean”) Solar and Wind
China sweeps up lithium supplies in acquisition blitz
By Paul Homewood, Not a Lot of People Know That, Nov 4, 2021
Wind Power Health Effects (latest from Scientific Reports)
By Robert Bradley Jr. Master Resource, Oct 28, 2021
Link to paper: Effects of low-frequency noise from wind turbines on heart rate variability in healthy individuals
By Chun-Hsiang Chiu, Nature Scientific Reports, Sep 8, 2021
Who needs windows anyway? Study shows homes near wind turbines need airtight shut windows
By Jo Nova, Her Blog, Oct 30, 2021
“How many heart attacks should we have today to avoid one heatwave in 2100?”
See links immediately above.
Greening deserts: India powers renewable ambitions with solar push
By Glenda Kwek, Bhadla, India (AFP) Nov 2, 2021
Energy and Environmental Review: November 1, 2021
By John Droz, Jr., Master Resource, Nov 1, 2021
Virginia’s Blackout Energy Plan (‘bloody expensive,’ says E&E News)
By Thomas Stacy II, Master Resource, Nov 2, 2021
Offshore wind in North Carolina: Five things to know from our series
By Charles Duncan, Spectrum Local News, NC, Oct 29, 2021
“Offshore wind could mean big business and clean energy for North Carolina.”
[SEPP Comment: Big business or bankruptcy, the answer is blowing in the wind?]
Alternative, Green (“Clean”) Energy — Other
Black carbon aerosols heating Arctic: Large contribution from mid-latitude biomass burning
The year-to-year spring variation in Arctic black carbon (BC) aerosol abundance is strongly correlated with biomass burning in the mid-latitudes. Moreover, current models underestimate the contribution of BC from biomass burning by a factor of three
Press Release, Nagoya University, Nov 4, 2021 [H/t WUWT]
Link to paper: Arctic black carbon during PAMARCMiP 2018 and previous aircraft experiments in spring
By Sho Ohata et al., Atmospheric Chemistry and Physics, Nov 4, 2021
[SEPP Comment: Based on between 03-03-2018 and 04-04-2018]
Landmark U.S. $4.5 Billion Louisiana Clean Energy Complex
Press Release, Air Products, Accessed Nov 5, 2021
Nacero to build $6B natural gas to gasoline plant in Luzerne County
By Bill O’Boyle, Times Leader, Pennsylvania, Oct 29, 2021
“’We will give everyday drivers zero sulfur, 100% domestic, low- and net zero-carbon gasoline for use in their existing vehicles without modification,’ said said Jay McKenna, Nacero’s CEO. ‘Our affordable and accessible products will clear the air and reduce global warming.’”
Carbon Schemes
Prince Charles urges radical rethink of our cities to combat climate change
By Paul Homewood, Not a Lot of People Know That, Oct 31, 2021
[SEPP Comment: Increase urbanization, and urban warming?]
People (Ordinary, that is) need to change their diet and flying habits to help planet, chief scientific adviser Sir Patrick Vallance warns
By Paul Homewood, Not a Lot of People Know That, Oct 29, 2021
California Dreaming
California Governor Gavin Newsom Proclaims Natural Gas To Be Zero-Carbon
By James Conca, Forbes, Nov 3, 2021
[SEPP Comment: The Governor decrees no C in CH4!]
Environmental Industry
Carl Pope on Energy: Exactly Backwards (old-school alarmist in denial)
By Robert Bradley Jr. Master Resource, Nov 3, 2021
Contradicting comment by David Middleton: “The world is already in an ‘energy crisis’ of sorts due to the tremendous misallocation of capital from functioning energy infrastructure to mythical energy infrastructure. This has largely been driven by the false perception that a massive reduction in greenhouse gas emissions is the only way to save our planet (cue George Carlin). As if this wasn’t bad enough, the COP 26 path ‘to net-zero emissions’ is ‘paved with’ nothing other than ‘bad assumptions’.”
If Only Climate Activists Cared About Elephants
By Jennifer Marohasy, Her Blog, Nov 2, 2021
“The problem for the elephants is hunting – illegal poaching – which was once such a problem for polar bears.”
Other Scientific News
Origins of modern wheat may provide clues to making it stronger
By Brian P. Dunleavy, Washington DC (UPI), Nov 1, 2021
Link to paper: Population genomic analysis of Aegilops tauschii identifies targets for bread wheat improvement
By Kumar Gaurav, et al, Nature Biotechnology, Nov 1, 2021
BELOW THE BOTTOM LINE
More money than brainosaurus
By John Robson, Climate Discussion Nexus, Nov 3, 2021
Link to video that may work: https://www.nbcnews.com/news/world/save-your-species-united-nations-uses-dinosaur-fossil-fuel-message-n1282628
[SEPP Comment: An example of the finest brains on this planet determined to fix climate?]
24 bottles of death on the wall
By John Robson, Climate Discussion Nexus, Nov 3, 2021
“A single eight-ounce glass of beer takes about 20 gallons of water to produce. The brewing process requires large amounts of electricity – to heat hot water and steam and then for refrigeration. Then there’s glass and aluminum for containers and plastic and cardboard for packaging.”
EU must be joking! VDL [ President of the European Commission] shamed for 31-mile private jet flight while hailing climate deal
By Paul Homewood, Not a Lot of People Know That, Nov 2, 2021
“No surprise that the EU troughers are at the front of the hypocrisy queue!”
[SEPP Comment: Not confirmed]
The COP26 menu is ‘like serving cigarettes at a lung cancer conference’
Climate and conservation groups have questioned the sustainability of the COP26 menu, which is almost 60 per cent meat or dairy based.
By Sarah Wilson, Big Issue, Nov 2, 2021
[SEPP Comment: Let them eat gruel! The meetings will be less costly to the environment!]
ARTICLES
1. We’re Safer From Climate Disasters Than Ever Before
Though it receives little mention from activists or the media, weather-related deaths have fallen dramatically.
By Bjorn Lomborg, WSJ, Nov. 3, 2021
TWTW Summary: The president of the Copenhagen Consensus and a visiting fellow at the Hoover Institution writes:
“Activists constantly talk about the existential threat climate change poses and the deaths natural disasters inflict—but they never quite manage to total up these deaths. One reason is that it’s easier to bend the data about disaster frequency than to bend death statistics. Death tolls tell a very clear story: People are safer from climate-related disasters than ever before.
“As this series of articles has covered already, many of the fearful descriptions you hear of souped-up hurricanes, heat waves and wildfires aren’t accurate. And estimates of costly but increasingly frequent climate damages are typically designed to mislead. One you see repeated often in the media is the National Centers for Environmental Information’s statistic that the number of natural disasters costing over $1 billion in damage is on the rise. But as this series explained in regard to flood costs, only measuring the total damage of natural disasters over time misses the important point—there’s much more stuff to damage today than there was several decades ago.
“As the world has gotten richer and its population has grown, the number and quality of structures in the path of floods, fires, and hurricanes have risen. If you remove this variable by looking at damage as a percent of gross domestic product, it actually paints an optimistic picture. The trend of weather-related damages from 1990 to 2020 declined from 0.26% of global GDP to 0.18%. A landmark study shows this has been the trend for poor and rich countries alike, regardless of the types of disaster. Economic growth and innovation have insulated all sorts of people from floods, droughts, wind, heat and cold.
“Still, it’s easy to misuse the data to make things seem worse than they actually are. The International Disaster Database—the biggest disaster data depository in the world—attempts to register every catastrophe around the globe using reports from sources ranging from the press to insurance companies to United Nations agencies. But because the internet and proliferation of media has made it so much easier to access information today, the database records small natural disasters from 1980 onward that in prior decades wouldn’t have been recorded.
“This skews the database by making it appear there are more total disasters today than the past. (Several U.N. agencies have twisted this data to say just that.)”
Lomborg gives specific examples of data manipulation such as earthquakes and hurricanes. He then continues:
“Death totals, on the other hand, are much less pliable. While reports on climate catastrophes multiplied over the last century, large-scale deaths have been consistently recorded. In fact, the disaster database’s death toll is very close to official estimates. And that data tells an incredible and heartening story. A century ago, almost half a million people died on average each year from storms, floods, droughts, wildfires and extreme temperatures. Over the next 10 decades, global annual deaths from these causes declined 96%, to 18,000. In 2020, they dropped to 14,000.
“Unsurprisingly, the media this year has been filled to the brim with coverage of natural disasters, from the Northwestern Heat Dome to floods in Germany and China. Yet it has conveniently left out the total death toll. So far 5,500 people have died from climate-related disasters in 2021. Using previous years’ data to extrapolate, climate-related deaths will probably total about 6,600 by the end of the year. That’s almost 99% less than the death toll a century ago. The global population has quadrupled since then, so this is an even bigger drop than it looks.
“As has been the case across this series of articles, economic growth and technological innovation get the credit for our improving position. Human beings are pretty good at adapting to their environment, even if it’s changing. Keep that in mind when you see another worried headline about climate disasters.”
*********************
2. Today’s Historic Summit Agreements Don’t Have Much of a Future
Whether it’s COP26, the G-7, or the G-20, few of the politicians signing deals have the mandate to do so.
By Joseph C. Sternberg, WSJ, Nov. 4, 2021
[SEPP Comment: Discussed in the This Week section above.]
*********************
3. Steep Cuts to Carbon Emissions Gain Stronger Economic Backing
New research on the cost of climate change lends support to tougher pledges ahead of the Glasgow climate conference
By Greg Ip, WSJ, Oct 31, 2021
TWTW Summary: Under a photo of chimneys blackening the skies, the reporter discusses the various models used to forecast future damage from the use of fossil fuels (all assuming IPCC claims are correct) then writes:
“Michael Greenstone, a University of Chicago economist who led the Obama administration’s calculation of the social cost of carbon, said this is no longer good enough. Mr. Nordhaus’ estimate of 2% GDP loss is ‘not grounded in empirical evidence,’ he said. ‘Nor does it capture and reflect the heterogeneity, the differences in climate impacts around the world.’
“He said that since 2010, 438 empirical studies of climate impact have been released, none of which are reflected in established models. Mr. Greenstone co-founded the Climate Impact Lab to put climate economics on an empirical foundation. Its findings break important new ground. For example, they show the two biggest sources of damage from climate are premature death and decreased labor productivity due to extreme heat, neither of which figure prominently in established models.”
In an electronic post to the article, Haapala wrote: Empirical foundation such as the photo of smokestacks blackening the skies with invisible carbon dioxide? There is no significant physical evidence that CO2 is causing dangerous global warming, just speculation using computer models as solid as those used to claim that the US will run out of oil and gas by the end of the 20th century. Since John Tyndall started using early spectroscopy in 1859 to show the importance of the greenhouse effect for human existence, we have had over 150 years of laboratory experiments backed by over 40 years of atmospheric observations showing no dangerous warming from CO2 – all ignored by the IPCC and the US government! US climate science ignores the space age. Don’t believe me? Show me the physical evidence that I’m wrong!
Related
via Watts Up With That?
November 8, 2021 at 04:43AM

{kind=link}
{kind=link}