
Guest Essay by Kip Hansen — 22 June 2022
Why do we have so many wildly varying answers to so many of the important science questions of our day? Not only varying, but often directly contradictory. In the health and human diet field, we have findings that meat/salt/butter/coffee/vitamin supplements are good for human health and longevity (today…) and simultaneously or serially, dangerous and harmful to human health and longevity (tomorrow or yesterday). The contradictory findings are often produced through analyses using the exact same data sets. We are all so well aware of this in health that some refer to it as a type of “whiplash effect”.
[Note: This essay is almost 3000 words – not a short news brief or passing comment. It discusses an important issue that crosses science fields. – kh ]
In climate science, we find directly opposing findings on the amount of ice in Antarctica (here and here) both from NASA or the rate at which the world’s oceans are rising, or not/barely rising. Studies are being pumped out which show that the Earth’s coral reefs are (pick one) dying and mostly dead, regionally having trouble, regionally are thriving, or generally doing just fine overall. Pick almost any scientific topic of interest to the general public today and the scientific literature will reveal that there are answers to the questions people really want to know – plenty of them – but they disagree or directly contradict one another.
One solution to this problem that has been suggested is the Many-Analysts Approach. What is this?
“We argue that the current mode of scientific publication — which settles for a single analysis — entrenches ‘model myopia’, a limited consideration of statistical assumptions. That leads to overconfidence and poor predictions.
To gauge the robustness of their conclusions, researchers should subject the data to multiple analyses; ideally, these would be carried out by one or more independent teams. We understand that this is a big shift in how science is done, that appropriate infrastructure and incentives are not yet in place, and that many researchers will recoil at the idea as being burdensome and impractical. Nonetheless, we argue that the benefits of broader, more-diverse approaches to statistical inference could be so consequential that it is imperative to consider how they might be made routine.” [ “One statistical analysis must not rule them all” — Wagenmakers et al. Nature 605, 423-425 (2022), source or .pdf ]
Here’s an illustration of the problem used in the Nature article above:
This chart shows that nine different teams analyzed the UK data on Covid spread in 2020:
“This paper contains estimates of the reproduction number (R) and growth rate for the UK, 4 nations and NHS England (NHSE) regions.
Different modelling groups use different data sources to estimate these values using mathematical models that simulate the spread of infections. Some may even use all these sources of information to adjust their models to better reflect the real-world situation. There is uncertainty in all these data sources, which is why estimates can vary between different models, and why we do not rely on one model; evidence from several models is considered, discussed, combined, and the growth rate and R are then presented as ranges.” … “This paper references a reasonable worst-case planning scenario (RWCS).”
Nine teams, all have access to the same data sets, nine very different results, ranging from, “maybe the pandemic is receding” (R includes less than 1) to “this is going to be really bad” (R ranges from 1.5 to 1.75). How do policy makers use such results to formulate a pandemic response? The range of results is so wide that it represents the question itself: “Is this going to be OK or is it going to be bad?” One group was quite sure it was going to be bad (and they seem to have been right). At that time, with these results, the question remained unanswered.
Wagenmakers et al. then say this:
“Flattering conclusion
This and other ‘multi-analyst’ projects show that independent statisticians hardly ever use the same procedure. Yet, in fields from ecology to psychology and from medicine to materials science, a single analysis is considered sufficient evidence to publish a finding and make a strong claim. “ … “Over the past ten years, the concept of P-hacking has made researchers aware of how the ability to use many valid statistical procedures can tempt scientists to select the one that leads to the most flattering conclusion.”
But, not only tempted to select the procedures that lead to the “most flattering” conclusion, but also to the conclusion that best meets the needs of agreeing with the prevailing bias of their research field. [ ref: Ioannidis ].
Wagenmakers et al. seem to think that this is just about uncertainty: “The dozen or so formal multi-analyst projects completed so far (see Supplementary information) show that levels of uncertainty are much higher than that suggested by any single team.”
Let’s see where this goes in another study, “A Many-Analysts Approach to the Relation Between Religiosity and Well-being”, which was co-authored by Wagenmakers:
“Summary: In the current project, 120 analysis teams were given a large cross-cultural dataset (N = 10,535, 24 countries) in order to investigate two research questions: (1) “Do religious people self-report higher well-being?” and (2) “Does the relation between religiosity and self-reported well-being depend on perceived cultural norms of religion?”. In a two-stage procedure, the teams first proposed an analysis and then executed their planned analysis on the data.
Perhaps surprisingly in light of previous many-analysts projects, results were fairly consistent across teams. For research question 1 on the relation between religiosity and self-reported well-being, all but three teams reported a positive effect size and confidence/credible intervals that included zero. For research question 2, the results were somewhat more variable: 95% of the teams reported a positive effect size for the moderating influence of cultural norms of religion on the association between religiosity and self-reported well-being, with 65% of the confidence/credible intervals excluding zero.”
The 120 analysis teams were given the same data set and asked to answer two questions. While Wagenmakers calls the results “fairly consistent”, what the results show is that they are just not as contradictory as the Covid results. On the first question, 117 teams found a “positive effect size” whose CI excluded zero. All these teams agreed at least on the sign of the effect, but not the size. 3 teams found an effect that was negative or whose CI included zero. The second questioned fared less well. While 95% of the teams found a positive effect, only 65% had CIs excluding zero.
Consider such results for the effect of some new drug – the first question looks pretty good despite great variation in positive effect size but the second question has 45% of analysis teams reporting positive effects which had CIs that included zero – which means a null effect. With such results, we might be “pretty sure” that the new drug wasn’t killing people, but not so sure that it was good enough to be approved. I would call for more testing.
But wait …. can’t we just average the results of the 120 teams and get a reliable answer?
No, averaging the results is a very bad idea. Why? It is a bad idea because we do not understand, at least at this point, why the analyses arrived at such different results. Some of them must be “wrong” and some of them may be “right”, particularly with results that contradict one another. In 2020, it was wrong, incorrect that Covid was receding in the UK. Should the incorrect answers be averaged into the maybe-correct answers? If four drug analyses say “this will harm people” and 6 analyses say “this will cure people” – do we give it a 60/40 and approve it?
Let’s look at a sports example. Since soccer is the new baseball, we can look at this study: “Many Analysts, One Data Set: Making Transparent How Variations in Analytic Choices Affect Results”. (Note: Wagenmakers is one of a dizzying list of co-authors). Here’s the shortest form:
“Twenty-nine teams involving 61 analysts used the same data set to address the same research question: whether soccer referees are more likely to give red cards to dark-skin-toned players than to light-skin-toned players. Analytic approaches varied widely across the teams, and the estimated effect sizes ranged from 0.89 to 2.93 (Mdn = 1.31) in odds-ratio units. Twenty teams (69%) found a statistically significant positive effect, and 9 teams (31%) did not observe a significant relationship.”
If you want to understand this whole Many-analysts Approach, read the soccer paper linked just above. It concludes:
“Implications for the Scientific Endeavor: It is easy to understand that effects can vary across independent tests of the same research hypothesis when different sources of data are used. Variation in measures and samples, as well as random error in assessment, naturally produce variation in results. Here, we have demonstrated that as a result of researchers’ choices and assumptions during analysis, variation in estimated effect sizes can emerge even when analyses use the same data.
The main contribution of this article is in directly demonstrating the extent to which good-faith, yet subjective, analytic choices can have an impact on research results. This problem is related to, but distinct from, the problems associated with p-hacking (Simonsohn, Nelson, & Simmons, 2014), the garden of forking paths (Gelman & Loken, 2014), and reanalyses of original data used in published reports.“
It sounds like Many-Analysts isn’t the answer – many analysts produce many analyses with many, even contradictory, results. Is this helpful? A little, as it helps us to realize that all the statistical approaches in the world do not guarantee a correct answer. They each produce, if applied correctly, only a scientifically defensible answer. Each new analysis is not “Finally the Correct Answer” – it is just yet another analysis with yet another answer.
Many-analyses/many-analysts is closely related to the many-models approach. The following images show how many-models produce many-results:
[ Note: The caption is just plain wrong about what the images mean….see here. ]
Ninety different models, projecting both the past and future, all using the same basic data inputs, produce results so varied as to be useless. Projecting their own present, (2013) Global Temperature 5-year Running Mean has a spread of 0.8°C with all but two of the projections of the present being higher than observations. This unreality widens to 1°C nine years in CMIP5’s future in 2022.
And CMIP6? Using data to 2014 or so (anyone know the exact date?) they produce this:
Here we are interested not in the differences between observed and modeled projections, but in the spread of the different analyses – many show results that are literally off the top of the chart (and far beyond any physical possibility) by 2020. The “Model Mean” (red bordered yellow squares) is nonsensical, as it includes those impossible results. Even some of the hindcasts (projections of known data in the past) are impossible and known to be more than wrong (for instance, 1993 and 1994 shows one model projecting temperatures below -0.5) while another in 1975-1977 hindcasts temperatures a full degree too high).
A 2011 paper compared different analyses of possible sea level rise in 5 Nunavut communities (in Alaska). It presented this chart for policymakers:
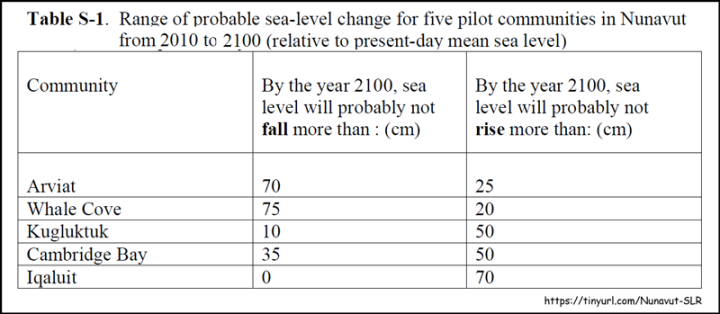
For each community, the spread of the possible SLR given is between 70 and 100 cm (29 to 39 inches) — for all but one locality, the range includes zero. Only for Iqaluit is even the sign (up or down) within their 95% confidence intervals. The combined analyses are “pretty sure” sea level will go up in Iqaluit. But for the others? How does Whale Cove set policies to prepare for either a 29 inch drop in sea level or an 8 inch rise in sea level? For Whale Cove, the study is useless.
How can multiple analyses like these add to our knowledge base? How can policymakers use such data to make reasonable, evidence-based decisions?
Answer: They can’t.
The most important take-home from this look at the Many-Analysts Approach is:
“Here, we have demonstrated that as a result of researchers’ choices and assumptions during analysis, variation in estimated effect sizes can emerge even when analyses use the same data.
The main contribution of this article is in directly demonstrating the extent to which good-faith, yet subjective, analytic choices can have an impact on research results.” [ source ]
Let me interpret that for you, from a pragmatist viewpoint:
[Definition of PRAGMATIST: “someone who deals with problems in a sensible way that suits the conditions that really exist, rather than following fixed theories, ideas, or rules” source ]
The Many-Analysts Approach shows that research results, both quantitative and qualitative, are primarily dependent on the analytical methods and statistical approaches used by analysts. Results are much less dependent on the data being analyzed and sometimes appear independent of the data itself.
If that is true, if results are, in many cases, independent of the data, even when researchers are professional, unbiased and working in good faith then what of the entire scientific enterprise? Is all of the quantified science, the type of science looked at here, just a waste of time, useless for making decisions or setting policy?
And if your answer is Yes, what is the remedy? Recall, Many-Analysts is proposed as a remedy to the situation in which: “in fields from ecology to psychology and from medicine to materials science, a single analysis is considered sufficient evidence to publish a finding and make a strong claim.” The situation in which each new research paper is considered the “latest findings” and touted as the “new truth”.
Does the Many-Analysts Approach work as a remedy? My answer is no – but it does expose the unfortunate, for science, underlying reality that in far too many cases, the findings of analyses do not depend on the data but on the methods of analysis.
“So, Mr. Smarty-pants, what do you propose?”
Wagenmakers and his colleagues propose the Many-Analysts Approach, which simply doesn’t appear to work to give us useful results.
Tongue-in-cheek, I propose the “Locked Room Approach”, alternately labelled the “Apollo 13 Method”. If you recall the story of Apollo 13 (or the movie), the solution to an intractable problem was solved by ‘locking’ the smartest engineers in a room with a mock-up of the problem with the situation demanding an immediate solution and they had to resolve their differences in approach and opinion to find a real world solution.
What science generally does now is the operational opposite – we spread analytical teams out over multiple research centers (or lumped into research teams at a “Center for…”) and have them compete for kudos in prestigious journals, earning them fame and money (grants, increased salaries, promotions based on publication scores). This leads to pride-driven science, in which my/our result is defended against all comers and contrary results are often denigrated and attacked. Science Wars ensue – volleys of claims and counter-claims are launched in the journals – my team against your team – we are right and you are wrong. Occasionally we see papers that synopsize all competing claims in a review paper or attempt a meta-analysis, but nothing is resolved.
That is not science – that is foolishness.
There are important issues to be resolved by science. Many of these issues have plenty of data but the quantitative answers we get from many analysts vary widely or are contradictory.
When the need is great, then the remedy must be robust enough to overcome the pride and infighting.
Look at any of the examples in this essay. How many of them could be resolved by “locking” representatives from each of the major currently competing research teams in a virtual room and charging them with resolving the differences in their analyses in an attempt to find not a consensus, but the underlying reality to the best of their ability? I suspect that many of these attempts, if done in good faith, would result in a finding of “We don’t know.” Such a finding would produce a list of further research that must be done to resolve the issue and clarify uncertainties along with one or more approaches that could be tried. The resultant work would not be competitive but rather cooperative.
The Locked Room Approach is meant to bring about truly cooperative research, in which groups peer-review each other’s research designs before the time and money are spent; in which groups agree upon the questions needing answers in advance; agree upon the data itself, ask if it is sufficient or adequate or is more data collection needed?; and agree which groups will perform which necessary research.
There exist, in many fields, national and international organizations like the AGU, the National Academies, CERN, the European Research Council and the NIH that ought to be doing this work – organizing cooperative focused-on-problems research. There is some of this being done, mostly in medical fields, but far more effort is wasted on piecemeal competitive research.
In many science fields today, we need answers to questions about how things are and how they might be in the future. Yet researchers, after many years of hard work and untold research dollars expended, can’t even agree on the past or on the present for which good and adequate data already exists.
We have lots of smart, honest and dedicated researchers but we are allowing them to waste time, money and effort competing instead of cooperating.
Lock ‘em in a room and make ‘em sort it out.
# # # # #
Author’s Comment:
If only it were that easy. If only it could really be accomplished. But we must do something different or we are doomed to continue to get answers that contradict or vary so widely as to be utterly useless. Not just in CliSci, but in medicine, the social ‘sciences’, biology, psychology, and on and on.
Science that does not produce new understanding or new knowledge, does not produce answers that society can use to find solutions to problems or science that does not correctly inform policy makers, is USELESS and worse.
Dr. Judith Curry has proposed such cooperative efforts in the past such as listing outstanding questions and working together to find the answers. Some efforts are being made with Cochrane Reviews to find out what we can know from divergent results. It is not all hopeless – but hope must motivate action.
Mainstream Climate Science, those researchers that make endless proclamations of doom to the Mainstream Media, are lost on a sea of prideful negligence.
Thanks for reading.
# # # # #
via Watts Up With That?
June 23, 2022 at 08:34AM
