
Three reports provide data on hollowing out the alternative energy (non-hydrocarbon) sector. Firstly an update from E2 $22 Billion in Clean Energy Projects Cancelled in First Half of 2025; $6.7 Billion Cancelled in June. Excerpts in italics with my bolds and added images.
Clean Economy Works | total projects cancelled, closed,
downsized by sector Aug. 2022-June 2025
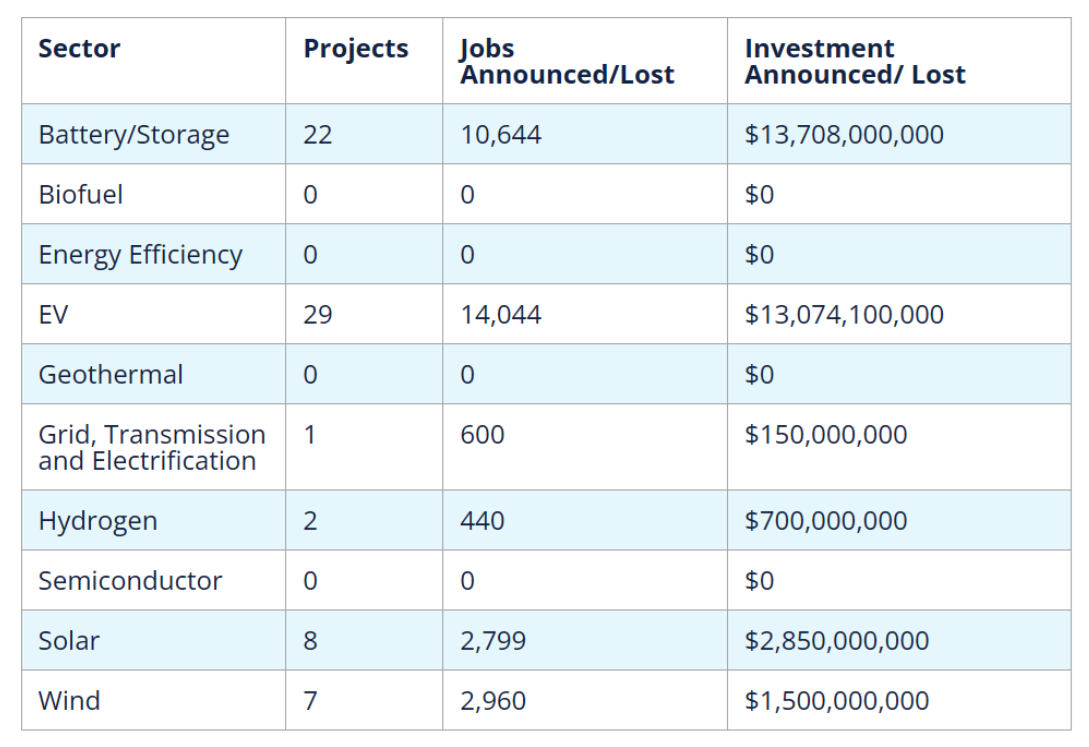
*totals will not match overall figures as some projects are categorized into multiple sectors
Businesses canceled, closed, and scaled back more than $22 billion worth of new factories and clean energy projects in the first half of 2025 after cancelling another $6.7 billion in June alone, according to E2’s latest monthly analysis of clean energy projects tracked by E2 and the Clean Economy Tracker.
The latest wave of cancellations — affecting five battery, storage, and electric vehicle factories in Colorado, Indiana, Michigan, New York, and Oregon — follows growing uncertainty among businesses as Congress was making the final push to effectively end federal clean energy tax credits. More than 5,000 jobs were lost to the cancellations and scales backs in June, bringing the total number of jobs lost to abandoned projects in 2025 to 16,500.
June’s cancellations were led by major automakers scaling back electric vehicle production investments. General Motors cancelled a $4.3 billion plan to expand its Orion plant in Michigan to build new electric pickups and instead shift its investments there to build 8-cylinder gas vehicles. Additionally, Toyota scaled back a $2.2 billion plan to retool a manufacturing plant in Indiana that was going to build a new three-row electric SUV, consolidating production to its Georgetown, Kentucky plant instead.
Cancellations, Closures, Downsizes
This tracking includes all projects, plants, operations, or expansions that were cancelled or closed since passage of the IRA in August 2022. This does not include announced layoffs that are not associated with a project downsizing unless there is a stated decease in production output. This list also does not include the transfer of project ownership, if production will continue under the new ownership, power purchasing agreements, or other similar type of announcements. Project delays or idling of facilities are not included unless there in an announced decrease in production or investment or unless the project will need to be restarted to proceed in the future.

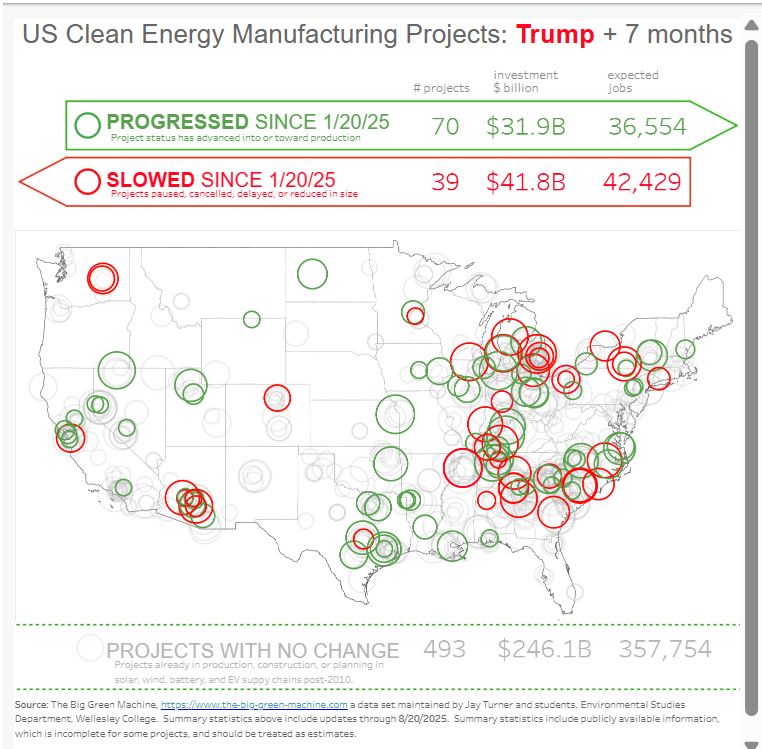
A second report is from Big Green Machine CLEAN ENERGY MANUFACTURING: TRUMP 47+ 7 MONTHS. Excerpts in italics with my bolds and added images.
What has happened to investment in US clean energy manufacturing and supply chains since Trump took office on January 20, 2025? Our Trump + 7 month tracker below was updated on August 20, 2025. You can also read our 6-month report below or download the report.
The Big Green Machine: Trump + 6 months report (released on July 29, 2025, based on data through July 20, 2025).
Since Donald Trump took office on January 20, 2025, newly announced investments in clean energy manufacturing projects have slowed dramatically, while the number of projects that have been paused, canceled, or closed has skyrocketed. Projects are being paused, cancelled, and closed at a rate 6 times more than during the same period in 2024 and 30 times more than during the same period in 2023.
The Big Green Machine tracks investments in the supply chain, from mine to factory, in the wind, solar, batteries, and electric vehicle industries. Over the past six months, 26 projects, totaling $27.6 billion in capital investment and creating 18,849 jobs, have been paused, canceled, or closed. During the same period, 29 new projects were announced, adding up to $3.0 billion in capital investment and 8,334 jobs.
This marks a dramatic reversal from the first six months of 2024. During that period, 54 new projects adding up to $15.9 billion in capital investment and 25,942 new jobs were announced. In comparison, 8 projects adding up to $4.1 billion in capital investment and 3,820 jobs were paused, canceled, or closed during the first six months of 2024.
That does not mean all activity in the clean energy sector has stopped. Since Trump took office, many previously announced projects have broken ground, started pilot production, or moved into full production. By our count, 39 projects adding up to $21.1 billion in capital investment and 25,269 jobs have advanced in the past six months. But the projects that are advancing are, on average, smaller in size than the projects that are slowing.
Other patterns are emerging with respect to which projects are advancing or slowing. Not surprisingly, projects counting on federal support in the form of loans and grants are more likely to be slowing. In addition, our tracking shows that projects located in communities with lower median household incomes and communities classified as disadvantaged are seeing a higher proportion of slowed projects, meaning that communities in need of opportunity are losing out.

Unlike the two above reports focusing on 2025 contractions, the third report from Canary media details the green energy bloodbath last year The cleantech companies that didn’t make it through 2024. Excerpts in italics with my bolds and added images.
From carbon removal startups to solar icons, the climate world saw a number of corporate flameouts this year. Here are some takeaways and lessons learned.
Examples included (among many others)

Solar sunsets
Arguably the most shocking cleantech corporate demise of 2024 was that of SunPower, a solar industry icon that grew from humble startup roots to a valuation in the billions, only to file for bankruptcy in August. Even as solar installations smash records in the U.S. and the federal government channels capital into onshoring solar panel production, SunPower found itself undone by China’s industrial policy might and its own boardroom missteps. High interest rates and other policy headwinds, like California’s NEM 3.0, didn’t help. Also Ubiquitous Energy, Toledo Solar

Solar installer bloodbath
High interest rates and rooftop solar incentive shifts in leading states rippled through the long tail of residential solar installers and led to scores of bankruptcies in the past two years, an unprecedented collapse.
Here are a few of the larger casualties from this year: Sunworks, a residential and commercial solar installer, filed for bankruptcy in February. Founded in 2002, Sunworks had developed 224 megawatts of solar projects across 15 states and employed 640 people. Titan Solar operated in 16 states and abruptly shut down its operations in June. Utah-based residential solar company Lumio filed for bankruptcy in September.

Energy storage setbacks
Armed with billions in investor capital, scores of storage startups have been aiming to dethrone energy stalwarts like lithium-ion and diesel generators — but in the words of The Wire’s Omar Little, “If you come at the king, you best not miss.”
These companies missed. Sweden’s Northvolt, once valued by investors at almost $12 billion, filed for bankruptcy in November in the year’s biggest battery bust. Ambri, an energy storage aspirant with technology based on the research of MIT professor Donald Sadoway, declared bankruptcy in May. Richmond, California–based Moxion Power laid off 101 workers in June and shuttered its doors, following a wave of hype for its 75-kilowatt portable lithium-ion batteries that it hoped would replace diesel generators. Two other notable failures in the storage sector: Ionic Materials, a 40-person MIT spin-out developing battery materials, Australian flow battery firm Redflow.

Removing carbon one VC dollar at a time
Running Tide was the largest marine carbon-removal startup and the first to sell ocean carbon credits. Its initial plan of removing carbon dioxide from the atmosphere and sequestering it in the ocean by growing and sinking kelp morphed into sinking wood chips coated with lime-kiln dust. Running Tide announced that it was folding in June after raising more than $54 million.
Unsustainable aviation
Chasing a clean fuels breakthrough, Fulcrum BioEnergy promised to transform municipal waste into sustainable aviation fuel through a low-emissions gasification process. Instead, the company incinerated hundreds of millions in funding from BP, United Airlines, Cathay Pacific, and Japan Airlines — and hundreds of millions more in municipal bonds. The firm ceased operations in May. Also Universal Hydrogen

Charger bankruptcy
Tritium, a major provider of high-speed EV chargers, went bust in April but found a buyer for its insolvent business in India-based Exicom, which claims it will keep Tritium’s U.S. factory in business. Tritium has sold roughly 13,000 chargers in 47 countries and claimed a 30 percent U.S. market share for direct-current fast chargers in 2023.

Zero to 60 and back to zero with EVs
Luxury EV maker Fisker went bankrupt again; electric-van maker Arrival went bankrupt and sold its assets to another struggling EV maker, Canoo, which is currently furloughing employees; Cake, a Swedish e-motorcycle startup, sold 6,000 bikes but filed for bankruptcy in February after raising more than $75 million.
Arcimoto, Faraday Future, Mullen Automotive, and Workhorse Group are publicly traded EV companies but are facing delisting warnings, paltry revenue, and valuations that are rapidly approaching zero. Nikola stock is down by 90 percent year to date.

Comment
These reports are from green energy enthusiasts and promoters, expressing concerns without questioning the so-called transition to zero carbon. They really do want to pave farmland over with solar and wind installations. The rest of us understand that the whole green economy notion is delusional and needs dismantling ASAP. The creative destruction of these misbegotten enterprises is a step in the right direction.

via Science Matters
August 26, 2025 at 12:48PM

